|
|
| |
|
|
| 搜 索:
热 点: 好品牌科技网创始人、高清家电网总编辑范贵宾 荣获2021金领奖“中国杰出青年创新30人”
|

例如,这个。

事实上,一个女人在画口红。
好了!真·眼睛瞎了也看不到什么。

现在,人工智能可以理解这样一个人不能理解的地图。
密歇根大学、网易伏羲AI实验室、北航团队共同开发了AI项目-NeuralMagiceye,专门从2D图像中识别3D物体。

也可以是动画的类型。

AI是怎么做到的?让我们先看看。
自动立体图的生成原理简单来说,通过训练深度卷积神经网络(CNN),通过自我监督学习的方式充分训练大型3D对象数据集,AI可以很好地识别2D纹理中的3D立体图。
在训练AI之前,必须了解自动立体图的生成原理。
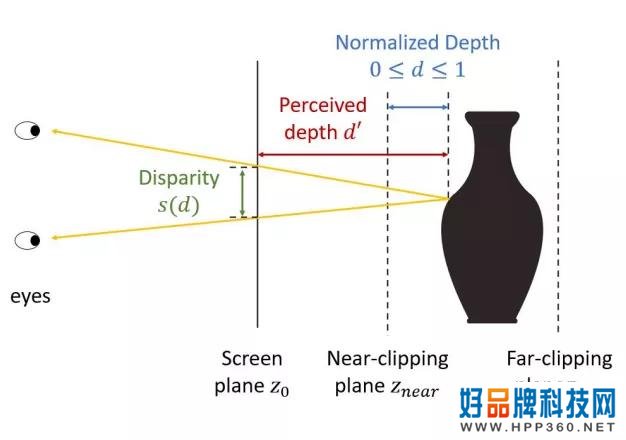
自动立体图其实和普通立体图一样,但是没有3D眼镜就看到了。
3D眼镜从稍微不同的角度向左眼和右眼呈现同一物体的二次元图像,使我们能够通过双眼的差异重建原始物体。
以适当的视线观看,自动立体图也是如此,双眼差异存在于重复2D图案的相邻部分。重复图案之间的距离决定了立体图像的远近。
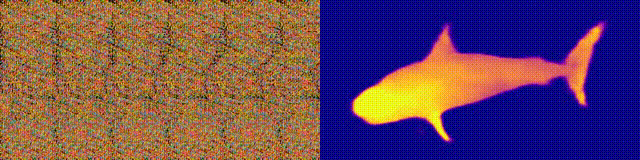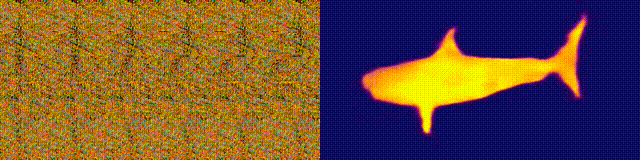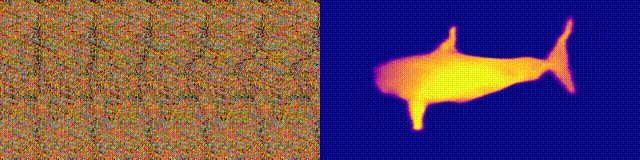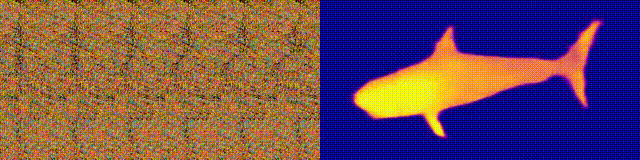
根据这样的原理,给出3D图像和条纹图案,可以生产自动立体图。
首先,将条纹铺平到整个输出图像中。然后,扫描输出图像中的每个像素,并根据需要的距离根据水平轴移动。
判断重复2D图案之间的距离是这次AI训练的关键。
AI是怎么做到的?简单概述,本次培训方法主要包括三个基本模块。
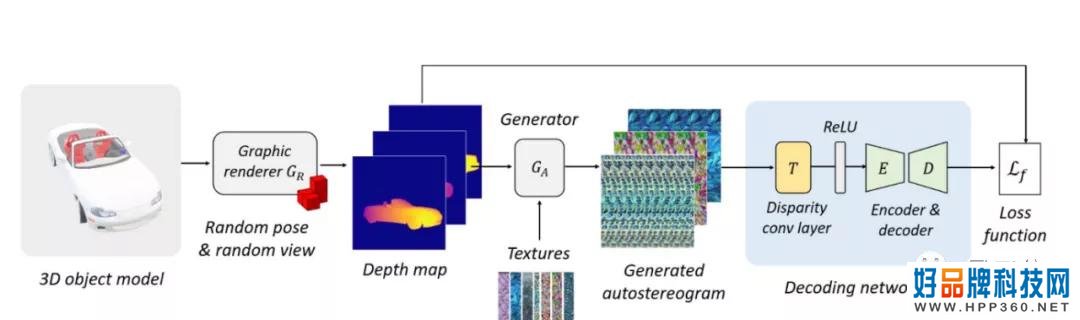
1、图形渲染器GR,从三维物体模型中渲染深度图片。
给定3D物体模型(例如3D网格),引进图形渲染器GR。
2.自动立体生成器GA。
深度编码并合成自动立体图。
3、解码网络,恢复深度。
近年来,深度CNN被广泛应用于像素预测任务,本文将网络训练为从像素到差距的映射。然而,在这种情况下,大多数图像区域将失去空间对应关系。
为了解决这个问题,本文提出了差异卷积的方法。
基本思想是计算各特征图中的特征向量及其水平邻域,并将其值保存在相应的特征通道中。
就这样。
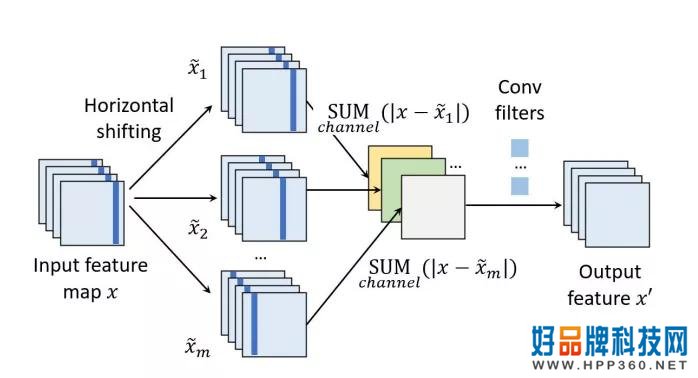
为了加快计算速度,可以将特征图沿水平轴圆周移动,然后输入并减少要素。
与标准卷积层相比,差异卷积不会引入额外的参数。
本次解码网结合了两种流行的网络结构,resnet18和unet。在这两种网络的输入端插入差异卷层和ReLU层,在差异卷层中,研究团队将最大的位移距离设定为输入图像高度的1/4。
之后,研究人员在ShapeNetCore训练解码网络-大型3D形状数据集复盖了55个常见对象类别,其中有50000多个独特的3D模型,随机将数据集分成训练集(90%)和测试集(10%)。
此外,团队还在线收集了718张2D纹理图(585张用于训练,133张用于测试),用于生成自动立体图。
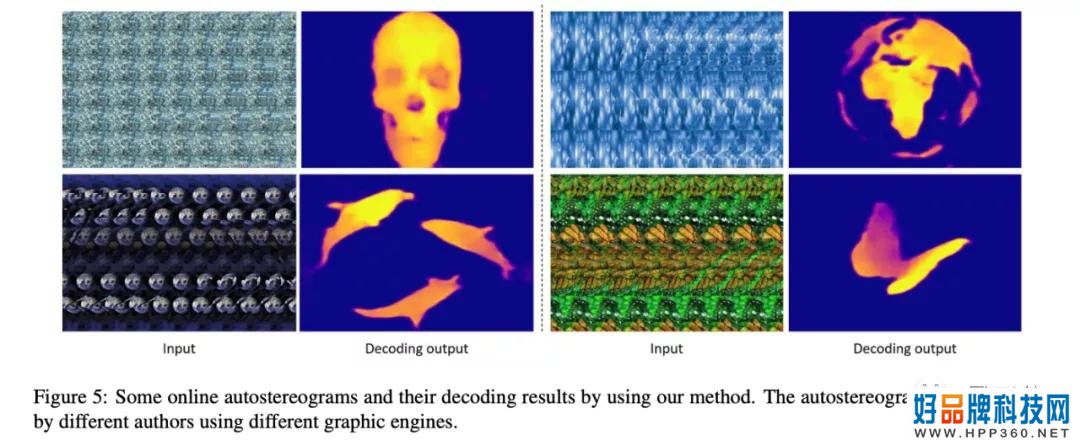
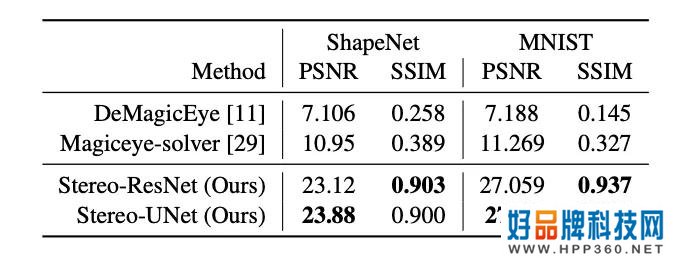
在解码精度的定量对比中,本文提供的方法表现出了良好的结果。
北航出身者的新作本次项目来自密歇根大学、网易伏羲AI实验室、北航共同完成。

其中第一作者是邹征夏,目前在密歇根大学博士后进行研究,他曾于2013年和2018年分别获得北航学士和博士学位。
研究方向是计算机视觉及其遥感,自动驾驶汽车和视频游戏的应用。

在北航学习期间,他获得了北航优秀博士论文奖,北航十佳博士研究生,北京市优秀毕业生,师从史振威教授。
前几天,他制作的SkyAR,制作了电影水平的天空之城,在AI圈引起了很多关注。

也有美术生崇拜的AI,自己把照片变成艺术画。

OneMoreThing最后分享小Tips。
AI也能识别立体图,我们不能输!
首先,放松眼部肌肉。
然后让左眼看到左上角的点,右眼看到右上角的点。
最后,逐渐调整视角。
在图像的上部看到3点后,慢慢调整眼睛的焦距,就能看到图像中的3D物体。
试试你的手吧!



关于我们 | 版权声明 | 联系我们 |
GQJD.Net 高清家电网 Copyrights 2008-2022 版权所有
京ICP备19050143号-3





